
百度前端训练营课程笔记(1):HTTP协议——同源策略与缓存控制
HTTP概述
HTTP请求和响应的结构
HTTP请求结构:
1 | |
HTTP响应结构:
1 | |
HTTP的应用
HTTP协议的应用依托于其请求和响应的结构。
最基本的应用:通过请求体在请求中携带数据、通过响应体从响应中获取数据。
此外很多HTTP协议的应用场景,都是通过一系列的请求头、响应头来完成的:
- 与同源策略相关的一系列响应头,如:
Access-Control-Allow-Origin、Access-Control-Allow-Headers等。 - 与缓存控制相关的一系列头,如:
Cache-Control、Date、Expires等。 - 与会话相关的
Cookie请求头。 - 与身份验证相关的
Authorization请求头。 - 与内容安全相关的
Content-Security-Policy响应头。
跨源与跨域
跨域的场景
- 项目的前后端服务部署在不同的域名下。
- 前端接入了部署在不同域名下的第三方服务,如Open API。
- 前端本地的开发服务器和后端的测试服务器在不同的机器,联调时会跨域。
同源策略
定义
指请求的内容与页面不在同一协议、同一域名、同一端口下,凡协议、域名、端口有一者不同,都是违背了同源策略。我们称这些情况是“跨源(Origin)”,“跨域(Domain)”只是“跨源”的一种情况。
同源策略只存在于浏览器端,不存在于 Android / iOS / Node.js 等其它环境。
限制
同源策略的限制主要有以下方面:
- Cookie、LocalStorage、indexDB等浏览器存储无法跨源读取。
- DOM对象无法跨源获取。
- 限制跨源AJAX请求。
其中最重要的是对跨源AJAX的限制。
同源策略对AJAX的限制
对于AJAX请求,同源策略限制的是浏览器JavaScript代码对响应的获取,而不会限制请求的发往服务端。即响应会照样发往服务器,但是对于返回的内容,JS代码无法获取到。
所以同源策略实际上是:
- 浏览器发送请求了吗?发了。服务器收到请求了吗?收到了。
- 服务器回复了吗?回复了。浏览器收到了吗?也收到了。
- 但是偏偏就是在最后一个阶段,浏览器没收了数据,不让JS代码读取。
如何解决跨域问题呢?
在 XMLHttpRequest 对象上有 withCredentials 属性,该属性表示在跨域时是否提供凭据信息(cookie、HTTP认证及客户端SSL证明等),为true则在发送请求时携带这些信息。
此时,后端返回的数据要注意两个响应头 Access-Control-Allow-Origin 和 Access-Control-Allow-Credentials 的值:
Access-Control-Allow-Origin:允许访问的源,即在这个字段中的源能够从后端获得资源。Access-Control-Allow-Credentials:布尔值,表示是否允许发送Cookie。
那么就有以下规则:
- 如果不携带Cookie,即
withCredentials: false,那么Access-Control-Allow-Origin设置为*也没有问题,也无需设置Access-Control-Allow-Credentials。 - 如果携带了Cookie,即
withCredentials: true,那么Access-Control-Allow-Origin必需为具体的Origin,并且Access-Control-Allow-Credentials必须为true。
总结来说,就是前后端要一起允许发送Cookie才可以正常使用Cookie,即 withCredentials 和 Access-Control-Allow-Credentials 都要为 true 。
但要注意,上述规则适用于简单请求!
假设我们有一个跨源请求,会永久修改后端数据(如 Method: DELETE )。如果该请求被服务端接收并执行成功,但是浏览器端JavaScript代码无法获取响应,那么我们就相当于在一个前端代码不知情的情况下,修改了数据。这显然是不合理的。
我们把请求会导致后端数据修改这种情况,认为是一种“副作用”。对于无副作用的请求可以直接发,拿不到响应也不会有影响;但对于有副作用的请求,则需要有一个限制的机制防止在获取不到响应的情况下对服务端产生影响。
这种会产生副作用的请求就不是简单请求,而是非简单请求,或者叫复杂请求。
简单请求与复杂请求
判断依据
- 请求的结构:
- 请求的Method。
- 请求头。
- 由于同源策略是对浏览器的限制,浏览器请求方式的一些特点也可以作为简单请求的判断依据:
- XMLHttpRequestUpload对象没有事件监听器。
- 请求中没有ReadableStream。
通过如上的判断依据,我们能够将请求根据有无副作用分为两类:简单请求与复杂请求。
其中请求的结构更常用于判断依据。
简单请求的请求结构
判断一个请求是否为简单请求:
- 请求方法是以下三种方法之一:
- HEAD
- GET
- POST
- HTTP的头信息不超出以下几种字段:
AcceptAccept-LanguageContent-LanguageLast-Event-IDContent-Type只限于三个值:application/x-www-form-urlencoded、multipart/form-data、text/plain
除此之外的都是复杂请求。
预检请求
对于复杂请求的跨源,则需要预检请求来帮忙。
由于复杂请求的副作用会产生在服务端,因此限制请求发送的限制机制由服务端来制定。
浏览器通过向服务端发送一个预检请求来决定是否进一步发送跨源的复杂请求。
假设有一个复杂请求需要发送,在这个请求发送前处于等待状态时,进行预检请求的发送,等到预检请求收到回应并且浏览器检查发现要发送的复杂请求符合预检请求中规定的允许的内容,这个复杂请求才会发送出去。
预检请求是一个确定不会产生副作用的请求,通过其响应,浏览器可以得到服务端对于跨源请求的策略,再以这个策略为依据,决定是否进一步发送跨源请求。
一旦服务器通过了“预检”请求,那么浏览器就知道服务器允许发送什么样的复杂请求了,所以以后每次浏览器就可以正常发送跨源的复杂请求,直到该预检请求的响应达到失效时间,才需要再次发送预检请求。
通过预检之后再发送符合规则的复杂请求就和发送简单请求一样了,请求会有一个 Origin 头信息字段,服务器的回应也都会有一个 Access-Control-Allow-Origin 头信息字段。
服务器收到“预检”请求以后,检查了 Origin 、 Access-Control-Request-Method 和 Access-Control-Request-Headers 字段以后,确认允许跨源请求,就可以做出回应,预检请求的作用涉及到以下响应头字段:
Access-Control-Allow-Methods:允许跨源的HTTP Method列表,多个值由逗号分隔,如GET, POST, PUT,允许*号。Access-Control-Allow-Headers:在跨源的请求中,允许包含的请求头列表,也是个支持多个值逗号分隔的字符串,如X-Custom-Header,允许*号。Access-Control-Max-Age:预检请求的有效期,每个浏览器厂商会拥有其默认值和允许的最大值,对于Chrome该值最大为2小时,单位:秒。
以上三个字段都是对预检请求的响应中才可以用的,用于服务端向客户端回复允许发送怎样的复杂请求。
复杂请求的响应头中的额外暴露字段
此外还有一个响应头首部,是用于非预检请求的响应的:
Access-Control-Expose-Headers:列出了哪些响应头字段可以作为响应的一部分暴露给外部,允许逗号分隔的多个值。
在默认情况下,只有以下响应头(即七种简单响应头)允许暴露给客户端访问到:
Cache-ControlContent-LanguageContent-LengthContent-TypeExpiresLast-ModifiedPragma
此时在复杂请求中,如果想要让客户端可以访问到其他的首部信息,就可以将它们在 Access-Control-Expose-Headers 里面列出来,如:
1 | |
缓存控制
缓存是一种保存资源副本并在下次请求时直接使用该副本的技术。通过使用缓存,能够显著的减少等待时间和网络流量,进而提升性能。
缓存的层次
浏览器缓存:
- Service Worker:一个服务器与浏览器之间的中间人角色,如果网站中注册了service worker那么它可以拦截当前网站所有的请求,进行判断(需要编写相应的判断程序),如果需要向服务器发起请求的就转给服务器,如果可以直接使用缓存的就直接返回缓存不再转给服务器,从而大大提高浏览体验。只能用于HTTPS。
- Memory Cache:内存缓存,不遵循HTTP语义的,由浏览器自行管理的缓存。是浏览器将缓存存储在内存中,读取速度快,但当前标签页一被关闭,这部分缓存就释放了。
- Disk Cache:硬盘缓存,遵循HTTP语义的缓存,根据浏览器请求头来触发。由于存储在硬盘中,因此速度不如内存缓存快,但是容量大。
- Push Cache:推送缓存,是 HTTP/2 中的内容,当以上三种缓存都没有命中时,它才会被使用。它只在会话(Session)中存在,一旦会话结束就被释放,并且缓存时间也很短暂。不常用。
网络缓存:
- 网络代理。
- CDN。
缓存的流程
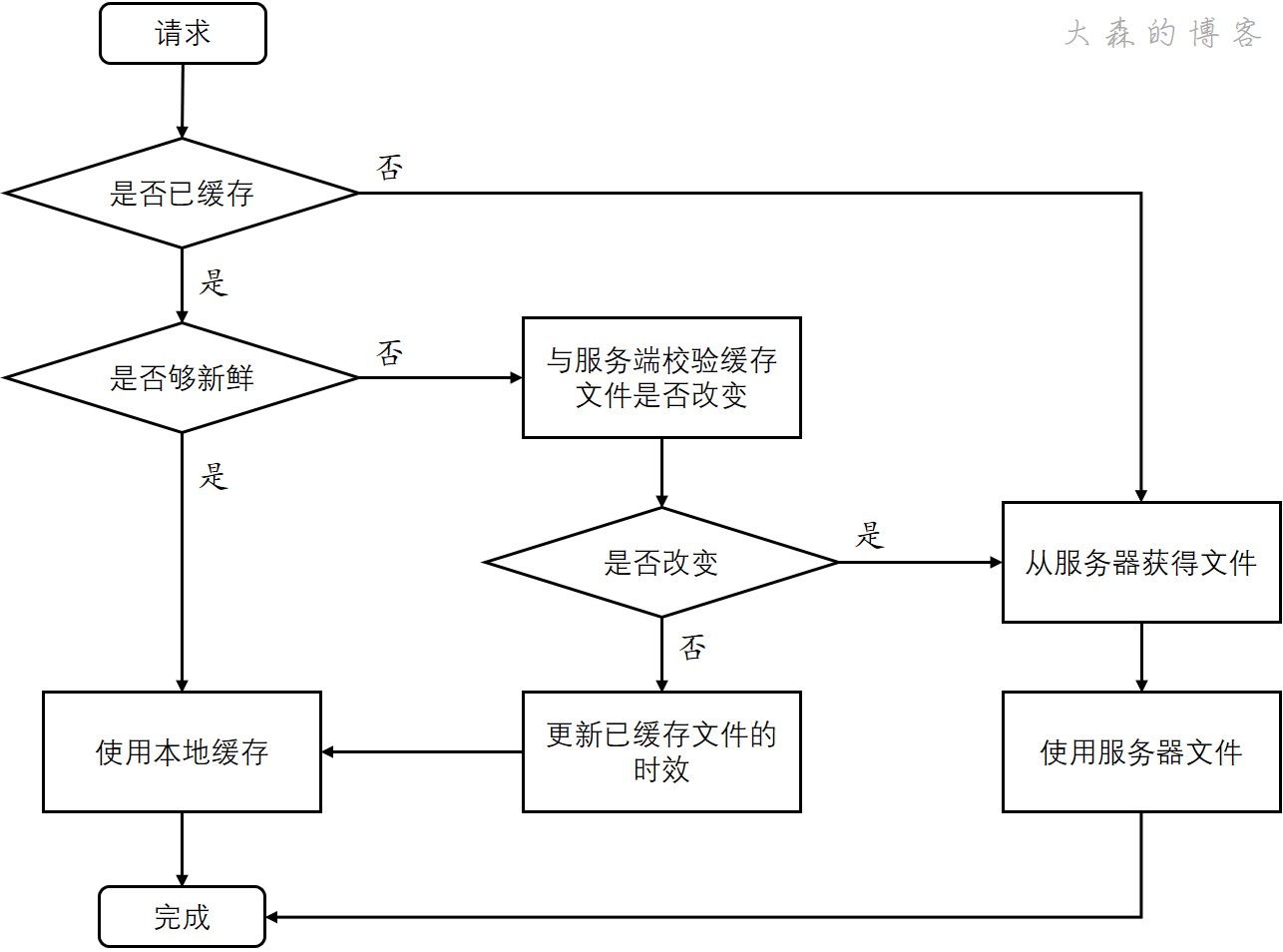
由于这里讲HTTP的缓存机制,因此这里的缓存主要指遵循HTTP语义的Disk Cache。
如何判断缓存新鲜度
判断一个缓存是否新鲜可用,那么就需要两个值的比较:资源已存在的时间和资源有效期。
如果一个资源已存在的时间要大于它的有效期,那么就认为它已经过期了,不再新鲜可用了。否则认为它还是有效的。这时就需要考虑这两个值如何获取。
如何计算资源有效期(freshness_lifetime):
- 如果
cache-control: no-cache,no-store或者pragma: no-cache存在,则资源有效期直接为0。 - 如果响应头中有
max_age值,那么资源有效期就是max_age的值。 - 如果响应头里没有
max_age但有expires,那么资源有效期就是expires的值减去date的值。date也是响应中的响应头字段,记录了该响应的创建时间,而响应则是和资源一一对应的。 - 如果存在
last_modified值,且未设置must_revalidate时,将会使用date的值和上次修改时间last_modified估计一个乐观的时间来作为其资源有效期,这里Chrome内核的计算方法是(date - last_modified) * 0.1。 - 都不符合,那么资源有效期就直接置为0,表示资源失效了,立即重新请求资源。
如何计算资源已存在的时间(current_age):
首先明确以下时间:
age_value:响应创造的时间到当前的服务器时间之差。date_value:date的值,now:当前时间。request_time:请求发送的时间。response_time:收到响应的时间。
然后计算:
apparent_age = max(0, response_time - date_value)response_delay = response_time - request_timecorrected_age_value = age_value + response_delaycorrected_initial_age = max(apparent_age, corrected_age_value)resident_time = now - response_timecurrent_age = corrected_initial_age + resident_time
以上计算过程仅供参考,由于规范有过改动且浏览器的实现可能有差异,只需要知道 freshness_lifetime 和 current_age 的含义和原理即可。
如何判断资源文件是否有更新
这一过程称为缓存文件协商,判断资源是否过期的过程是发生在服务端的。
缓存文件协商的过程是浏览器发送协商请求,服务端发送响应,根据响应的内容得知文件是否过期,具体如下:
- 如果缓存中的响应头设置了
cache-control: immutable,则请求中直接不添加if-none-match,if-modified-since字段(目前仅Firefox和Safari支持immutable)。 - 如果缓存中的响应头包含etag,则协商请求头中添加
if-none-match字段,值为缓存响应中的etag。etag认为是资源文件的哈希值,如果哈希没变,那么文件当然就没变。 - 如果缓存中的响应头包含
last-modified,则协商请求头中添加if-modified-since字段,值为缓存响应中的last-modified。 - 缓存是否生效的结果由服务端根据
if-none-match和if-modified-since计算得出,如果可以使用缓存,服务端返回304,否则返回200以及最新的响应内容。 - 可以看出:通常先判断etag,然后才是
last-modified,判断的优先级:etag > last-modified。
响应头的缓存控制字段
Cache-Control:
no-store:没有缓存no-cache:缓存但总是重新验证max-age=31536000:过期时间,秒must-revalidate:强制验证
Pragma:
no-cache:原本只在请求头中定义,但大家也都在响应头中用它。
常见的静态资源更新策略
- 对于低频更新的资源(js/css),在文件名上添加版本号(通常是ContentHash),并拥有一年甚至更长的
max-age。 - 当低频更新的资源变动了,只用在高频变动的资源文件(html)里做入口的改动。
